Doesn't matter how big your data is!
At some point in the last two decades, the size of our data became more important than the content of the data. The bigger, the better. We watched enviously as FAANG companies talked about optimizing hundreds of petabytes in their data lakes or data warehouses. For the vast majority of organizations though, the reality is sheer size doesn't matter. At the end of the day, it’s all about building the stack and collecting the data that's right for your company.
And there’s no one-size-fits all solution.
Stop Comparing Size
That may be a controversial thing to say when “big” has prefaced “data” in the label describing one of the predominant tech trends of our time. However, big data has always been defined beyond volume. For those that have forgotten, there are four other v’s: variety, velocity, value, veracity.
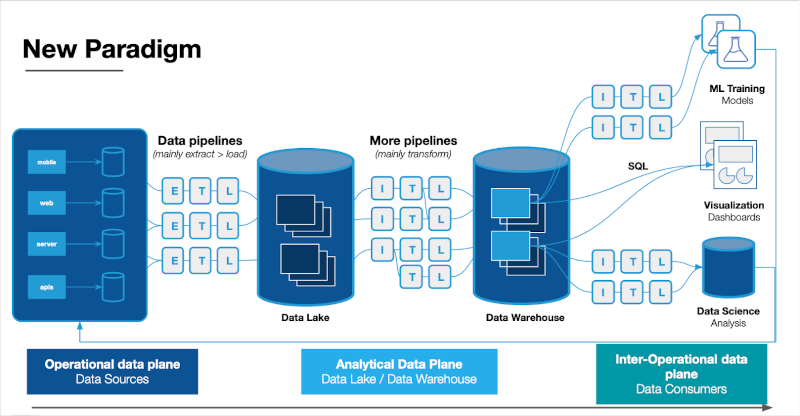
Volume has reigned supreme at the forefront of the data engineer’s psyche because, in the pre-Snowflake/AWS/Databricks era, the ability to store and process large volumes of data was seen as the primary architectural obstacle to business value. The old big data paradigm held you needed to collect as much data as possible (remember it was the new oil!) and build an architecture of corresponding scale. All of this data would rattle around as data scientists would use machine learning magic to glean previously inconceivable correlations and business insights from what were thought to be unrelated data sets.
Volume and value were one and the same. After all, who knew what data would be valuable for the machine learning black box?
Changes afoot
Inflating tables and terabytes may reveal a lack of organization, a potential for increased data incidents, and a challenge to overall performance. In other words, data teams may find themselves accumulating data volume at the expense of value, veracity, and velocity. This may be why Gartner predicts that by 2025, 70% of organizations will shift their focus from big to small and wide data.
Here are a few reasons why you should encourage your team to shift from a big (volume) data mindset and make your big data small(er).
Data is becoming productized
With the emerging modern data stack and concepts like the data mesh, what we have discovered is that data is not at its best when it’s rattling around unstructured and unorganized until a central data team prepares an ad-hoc snapshot deliverable or insight to business stakeholders. More data doesn't simply translate into more or better decisions, in fact it can have the opposite effect. To be data driven, domains across the business need access to meaningful near-real time data that fits seamlessly within their workflows.
This has resulted in a shift in the data delivery process that looks an awful lot like shipping a product. Requirements need to be gathered; features iterated; self-service enabled, SLAs established, and support provided. Whether the end result is a weekly report, dashboard, or embedded in a customer facing application, data products require a level of polish and data curation that is antithetical to unorganized sprawl.
Virtually every data team has a layer of data professionals who are tasked with processing raw data into forms that can be interpreted by the business. Your ability to pipe data is virtually limitless, but you are constrained by the capacity of humans to make it sustainably meaningful. In this way, working upfront to better define consumer needs and building useful self-serve data products can require less data.
The other constraints of course are quality and trust. You can have the best stocked data warehouse in the world, but the data won’t have any consumers if it can’t be trusted. Technologies like data observability can bring data monitoring to scale so there doesn't need to be a trade-off between quantity and quality, but the point remains data volume alone is insufficient to make a fraction of the impact of a well-maintained, high quality data product.
Machine learning is not that data hungry anymore
Machine learning was never going to process the entirety of your data stack to find the needle of insight in the haystack of random tables. It turns out that just like data consumers, machine learning models also need high-quality reliable data (maybe even more so). Data scientists devise specific models designed to answer difficult questions, predict outcomes of a decision, or automate a process. Not only do they need to find the data, they need to understand how it’s been derived.
By 2024, Gartner predicts the use of synthetic data and transfer learning will halve the volume of real data needed for machine learning.
Collection is easy, documentation and discovery are hard
Many data teams take a similar path in the development of their data operations. After reducing their data downtime with data observability, they start to focus on data adoption and democratization. However, democratization requires self-service, which requires robust data discovery, which requires metadata and documentation.
If we’re being honest, part of the challenge is no one outside the rare data steward enjoys documentation. But that shouldn’t make it less of a priority for data leaders (the more automation here the better).
Data Debt
Technical debt is when an easy solution will create re-work at some later point. It often builds exponentially and can crush innovation unless it’s paid in regular installments. For example, you might have multiple services running on an outdated platform, and reworking the platform means reworking the dependent services.
There have been many conceptions of data debt put forth, but one that resonates with me combines the concept of a data swamp, where too much poorly organized data makes it difficult to find anything, and over-engineered tables where long SQL queries and series of transformations have made the data brittle and difficult to put in context. This creates usability and quality issues downstream.
To avoid data debt, data teams should deprecate data assets at a higher rate.
Big isn't bad, but may not be a good thing either
All of this isn’t to say there is no value in "big" data. That would be an overcorrection. What I’m saying is that it’s becoming an increasingly poor way to measure the sophistication of a data stack and data team.
