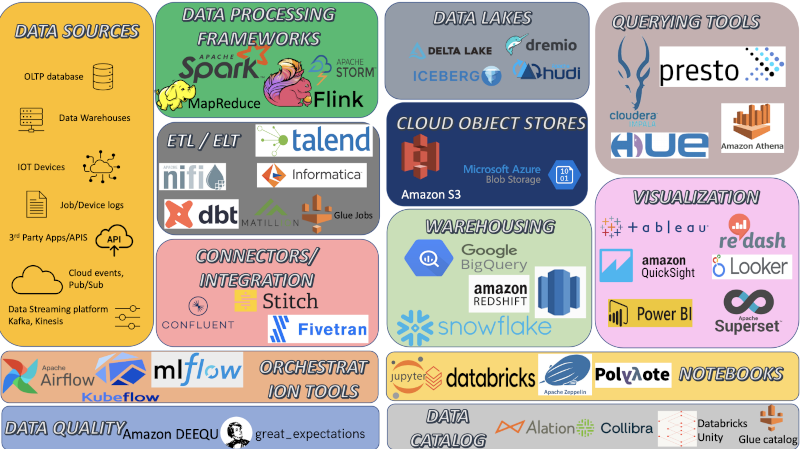
Modern Data Architecture
As time keeps progressing, technology keeps evolving, this includes recent discovery in data processing frameworks, visualization tools, ETL tools, Development notebooks, Data catalogs, etc.
Over the time, we have come across different terms like ETL, ELT, Reverse ETL. When it comes to database, jargon words that changed over time includes OLTP, OLAP, Big Data, Data Lake and Data Lakehouse, etc.
One of the highlighting difference between modern data stack and a legacy data stack is that modern data stack is cloud hosted and expects very less effort from users.
This post covers the list of technologies that I have come across in my experience which could be a part of modern data architectures.
Data Sources
Data, as we know, can be massive, can consist of complex data sets and exist in various forms. It can be of structured, semi-structured or unstructured. Data is exploding exponentially decade over decade. Diverse data sources play a major role in recent years which ranges from social data, machine data, streaming events, transactional data, etc. Many data sources can send huge volumes of data in real-time.
Data Processing Frameworks
This term became popular after the introduction of Hadoop’s MapReduce framework. There were days when MapReduce framework was celebrated all over the world. However, within a short span of time, some shortcomings in the MapReduce framework were addressed via in-memory computation frameworks such as Apache Tez and Apache Spark. In order to process real-time data, frameworks such as Flink, Samza, and Storm have been used effectively.
ETL
Tools used to extract, transform, and load curated data into target systems. Modern day ETL tools have changed a lot compared to traditional ETL tools which predominantly supported reading data only from transactional databases or data-warehouse. Traditional ETL are not scalable, flaky, expensive, and slow for the agile, data-driven modern organization. Modern ETL tools are also sometimes called Cloud ETL, due to the fact that modern ETL has evolved to execute jobs in cloud environments, which make them scalable, fast, and able to process data in real-time.
Connectors/Integrations
Recently, many connectors/integration tools have been developed to easily connect and ingest data from any cloud services, applications, and systems. Assists to quickly connect to critical enterprise applications, databases, and systems of records by using in-house or external connectors. It reduces the amount of effort and time required to transfer data from data sources to data sinks.
Data Lakes
A Data Lake, one of the latest approaches to store all forms of data, can be established in on-premises or in the cloud. All the cons of cloud file systems / object stores (AWS S3, Azure Blob, etc.) like CRUD functionality, Time travel, ACID Transactions, and Scalable metadata are the core attributes of Data Lakes. Databricks, which recently introduced the Data Lakehouse term, has taken the Spark journey to a higher level when it comes to data and Machine Learning.
Cloud Object Stores
Though cloud object stores like AWS S3, Azure Blob, Oracle Filesystem, IBM Filesystem have been built based on the characteristics of the Hadoop Distributed File System (HDFS), cloud object stores have been improved during recent years. Most of the cloud object stores come with an easy-to-use user interface, security, durability, and several cost efficiencies.
Data Warehousing
Compared to traditional data warehouses like Teradata and Oracle Analytics, modern cloud based warehouses are scalable and easy to implement. They have the features of:
- bulk loading and unloading data which consists of compressed files, different data formats like JSON, Avro, ORC, Parquet, etc.
- loading data from cloud file storages such as S3, Azure Blob using the concept of external tables
- granular security model and secured sharing of data between accounts
- replicating data and recovery from fail-over
Querying tools
A modern data stack can’t be complete without querying tools, which are used as the base editor for databases, datalakes, etc. Most of the tools leverage standard SQL as the querying language. There are specialist tools also, for example, Hue depends on Hive Query Language and Apache Pig needs Pig Latin Scripts for querying data. Irrespective of SQL or non-SQL, all the tools serve a similar purpose of helping users to understand the data, and their respective schemas and tables.
Visualization
Business intelligence (BI) combines business analytics, operational analytics, data mining, and data insights, to help organizations make data-driven decisions. Like other areas, Visualization tools are also moving towards the cloud. Most Visualization Dashboards can be created in realtime which saves us from worrying about infrastructure and the time associated with it. Recent additions like Superset and Redash makes for good competition in this area alongside existing tools like Tableau, Looker, Quicksight, etc.
Orchestration tools
This covers scheduling and monitoring of production jobs once the initial development phase has been completed. Apache Airflow and Apache Luigi have been popular for a while, Kubeflow and Databricks’s MLflow have been taking a lot of market share recently. Though all these tools serve common needs, every tool has some highlighting feature which stands out compared to the other orchestration tools. Depending on context and specific requirements, one would usually stand out over the others.
Notebooks
Other than the IDE, Notebooks are popular development environments for Machine Learning Engineers and Data Scientists. Primarily, a Notebook is used to develop data science code using Scala or Python programming languages. they also support execution of SQL queries, shell scripts, and other such utilities. Few notebooks like Databricks and AWS Sagemaker also support deployment of code directly into production environments (Live Tables, MLFlow).
Data Quality
Testing on datasets is always one of those aspects that people overlook. Amazon DeeQu and Great Expectations help to unit-test data by offering some automated profiling on our data and generating some tests automatically. This helps to verify the quality of many large production datasets within a stipulated amount of time.
Data catalog
Catalogs support data search, innovation, discovery, and a repository of metadata of information sources from across the enterprise, including data sets, business intelligence reports, visualizations, and conversations. Data catalogs became popular during the introduction of Hive catalog in Big Data environments. In traditional data stacks, data catalogs were primarily used to help developers more quickly find and understand data. But modern data catalogs are used to provide wider range of data intelligence solutions including data analytics, governance, and data discovery.
